La datafoot par ceux qui la font #1 – Julien Assuncao, blogueur et statisticien amateur
Julien Assuncao, connu dans le cybermonde sous le pseudo @Birdace, est l’un des quelques porte-drapeaux de la datafoot en France. Sur son blog Côté Stats, lancé au printemps dernier, il explore la manière dont le chiffre s’immisce dans l’analyse footballistique, histoire de voir ce que l’on pourrait en faire d’intéressant et novateur… Il est notamment l’auteur, avec Raphaël Cosmidis, d’un indispensable papier sur les « Expected Goals », une formule statistique très en vogue cette année (plus d’infos dans l’entretien). Ajoutez à cela sa contribution précieuse à notre projet Winning Formula (Julien nous ayant transmis des bases de données Football Manager), et vous comprendrez qu’il soit le premier invité de notre nouveau projet : « la datafoot par ceux qui la font », une série d’entretiens auprès de blogueurs et consultants travaillant avec le chiffre au quotidien, souvent de manière amatrice. Une façon pour nous de mettre en lumière ceux que l’on voit moins souvent que les professionnels de la data, mais qui pourtant contribuent pleinement à sa vitalité actuelle…

Comment es-tu arrivé à t’intéresser aux statistiques footballistiques ? Ta passion pour Football Manager y a-t-elle joué un rôle ?
Je me rappelle plus exactement comment je suis arrivé à Football Manager, juste que c’était avec la version 2004. Ça a forcément joué : quand on est intéressé par Football Manager, c’est probablement qu’on a déjà une attirance pour les chiffres à la base. C’était le cas pour moi, j’aimais ça avant de tomber dans le foot aussi. Du coup, j’ai voulu faire le lien assez naturellement.
D’abord de manière assez simple, en regardant les statistiques de joueurs à la fin des matchs puis en les adaptant au temps de jeu, etc. Ensuite, en lisant pas mal d’articles sur le sujet à côté, j’ai appris énormément de choses, souvent que je m’y prenais mal, et j’ai essayé de creuser un peu plus. C’est surtout quand je me suis mis à la programmation que j’ai pu approfondir mes observations en manipulant de plus gros échantillons (tirs, passes). Ce n’est pas une obligation mais ça permet d’aller plus loin dans l’analyse. Moins de temps pour récupérer les données, c’est davantage de temps pour les analyser.
C’est passionnant aussi parce qu’il s’agit d’un domaine relativement nouveau, en tout cas dans son application au football. Il reste énormément de choses à découvrir, les possibilités sont immenses pour le futur. C’est agréable d’en vivre le commencement.
A tes yeux, que peut apporter la datafoot à l’analyse footballistique ?
Un apport majeur de l’utilisation de données, c’est selon moi son objectivité. De toute évidence, on ne ressent pas les même choses devant le match et après coup. Il y a tellement d’événements dans un match de football que l’œil est incapable de tout suivre.
Même en faisant attention, on a toujours des idées préconçues sur une équipe ou un joueur, et l’analyse permet de les remettre en question. A côté de ça, il faut aussi se servir de ses impressions pour contextualiser les statistiques. Une statistique brute est souvent inutile.
C’est pourquoi, en ce qui me concerne, je m’en sers comme outil de vérification, mais le but est aussi d’arriver à expliquer des performances, individuelles ou collectives, en essayant d’isoler les facteurs déterminants et, si possible, de pouvoir prédire les futures performances. Pour l’instant, j’essaie surtout de trouver des moyens de donner plus de sens aux statistiques brutes, afin de m’en servir ensuite comme outils d’analyse.
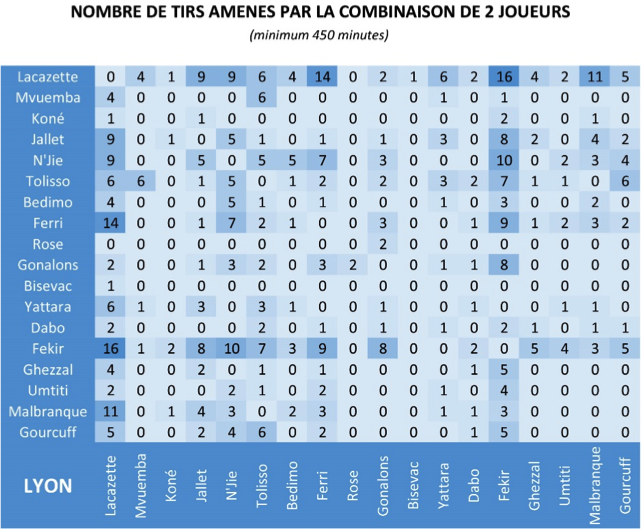
Échantillon statistique soulignant l’efficacité du tandem Fekir-Lacazette – © Birdace sur Libéro Lyon
Concrètement, où trouves-tu tes données ? Comment opères-tu pour les recueillir, les nettoyer, les classer, et in fine les analyser ?
Je n’ai pas de site secret à révéler, j’utilise régulièrement WhoScored quand je veux rapidement regarder les statistiques d’un joueur, StatsZone beaucoup pour récupérer des données, et ESPN aussi pour leurs comptes-rendus de matchs. Il y a bien un site moins connu, que j’utilise peu mais qui est excellent : www.football-data.co.uk. C’est l’endroit où aller pour récupérer des informations historiques sur les tirs, sous forme de csv.
Je récupère tout moi-même, j’essaye d’avoir le maximum automatisé pour pas faire ça à la main. Je fais tout avec R, un langage axé sur la manipulation de données et la création de graphiques, et Rstudio, le très bon environnement de développement qui va avec. Je fais tout avec ça : récupération, nettoyage, traitement, analyse. R possède aussi de puissants outils pour les graphiques. Sans rentrer dans les détails, la communauté est aussi active et de nombreux packages permettent d’étendre ses possibilités.
Tu as notamment travaillé sur les “Expected Goals”, concept statistique encore méconnu en France. Pourrais-tu nous en dire plus ?
Les Expected Goals viennent de l’observation, assez intuitive, que tous les tirs ne sont pas égaux. Je pense que tout le monde est d’accord pour dire qu’un tir de loin a moins de chance de faire but qu’un face-à-face avec le gardien et les Expected Goals essayent de mesurer ça plus précisément. La zone depuis laquelle le joueur tire est l’information qui a le plus d’importance mais il a ensuite été rajouté la partie du corps (pieds ou tête), la phase de jeu (coup franc, corner, dans le jeu, etc.), le type de passe (passe en profondeur, centre, remise de la tête, etc.). Maintenant, ça va encore plus loin avec des informations comme les attaques rapides, les rebonds ou le score, qui influe étonnement beaucoup.
C’est un très bon outil descriptif mais surtout prédictif, pour les équipes ou les joueurs. C’est-à-dire qu’il permet mieux de prédire les résultats d’une équipe, ou d’un joueur, d’une année à l’autre (ou d’une partie de saison à l’autre) mieux que les autres statistiques. Un bon exemple est Aston Villa, la saison dernière, dont l’entraîneur avait été prolongé après un début de saison canon mais avec des Expected Goals très mauvais et qui a été viré plus tard dans la saison, une fois les résultats rattrapant les chiffres.
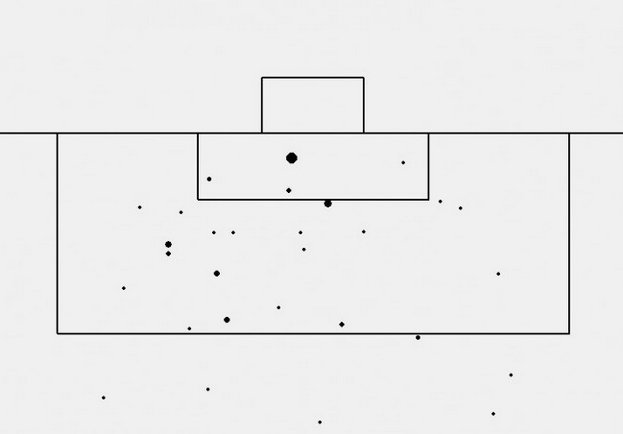
Tirs (non-bloqués) de Reims. La taille des points correspond à la valeur en ExpGoals.
Extrait de « Tour statistique de Ligue 1 : 4ème journée » – © Birdace
C’est une statistique pourtant loin d’être parfaite, la principale limite étant le manque d’informations sur le positionnement des défenseurs [nous y reviendrons dans un prochain billet, ndlr] même si quelques développements récents permettent de limiter ce problème. En dehors de ça, les Expected Goals ne sont pas une statistique accessible et on pourrait même les accuser d’être excessivement compliqués alors que d’autres, comme le ratio de tirs cadrés, permettent aussi des analyses intéressantes.
Mais au final, ça a permis de mieux isoler les différents facteurs importants dans la probabilité de convertir un tir en but, et de mettre des chiffres sur ce qui étaient des impressions : les centres sont peu efficaces, les contre-attaques sont à l’inverse très dangereuses, etc.
Quel regard portes-tu sur la “communauté” de blogueurs ou analystes qui explorent la datafoot ?
Déjà, c’est une communauté qui s’étend vraiment à vue d’œil. Enfin, je parle surtout de la partie anglophone, où il se passe rarement plus d’un jour sans voir un nouvel article passionnant sur le sujet. Il y aussi pas mal de gens qui écrivaient sur le football et faisait de l’analyse tactique qui incorpore de plus en plus de statistiques dans leurs articles et dès qu’on me demande, je transmets sans souci mes chiffres. En France, il y a notamment Florent Toniutti qui est un bon exemple [il répondra à ces mêmes questions dans un prochain épisode de “La datafoot par ceux qui la font”, ndlr].
Parmi la partie plus axée sur la « recherche », même s’il est toujours difficile d’être totalement ouvert sur ses résultats, il y a pas mal d’échanges entre nous. Chaque nouvelle statistique entraîne un débat et ça permet de faire avancer les choses. Je discute avec eux sur Twitter. Sur le blog c’est plus dur car je préfère me limiter à écrire en français. Ça permet de remettre en question son travail, parce qu’il y a toujours un risque de tomber amoureux de son modèle. Une communauté permet de garder les yeux ouverts. C’est aussi une source évidente d’inspiration, que ce soit par le travail de certains ou lors de discussions desquelles sortent souvent de nouvelles questions à explorer.
Quels sont aujourd’hui en France les besoins en termes de datafoot ? Quels leviers faudrait-il actionner pour populariser ces recherches ? Est-ce d’ailleurs souhaitable, selon toi…?
Je sais pas si ça fait partie de la question mais je ne pense pas qu’il y ait énormément de différence sur les besoins entre la France et le reste du monde (en dehors des États-Unis, qui sont effectivement un cas à part). Il y a clairement une évolution sur l’utilisation des statistiques dans les médias, il suffit de regarder des débriefs de matchs sur Canal+ ou beIN Sports, mais son utilisation peut faire mal à sa réputation si elle est mal maîtrisée.
Actuellement, contrairement à ce qu’on pourrait penser, les statistiques sont pour la plupart indicatrices d’un style plutôt que d’une qualité. Bien sûr qu’un attaquant qui marque souvent c’est positif, mais en revanche on ne sait toujours pas si c’est bien d’avoir un milieu qui tacle beaucoup ou un défenseur qui fait énormément de dégagements. Elles servent donc plus à décrire qu’à juger mais sont le plus souvent utilisées dans cette seconde optique.
C’est pourquoi il me semble important de rappeler la nécessité de toujours contextualiser une statistique. Elles sont tellement utilisées avec l’envie de prouver une opinion qu’il ne faut pas hésiter à les mettre en doute en se posant des questions. C’est parfois dommage de voir l’utilisation de statistiques limitée à une énumération du nombre de tirs ou de la possession à la fin d’un match, mais il faut avouer que c’est difficile de leur trouver une place [sur le sujet : Us et abus de la data, ndlr]. Il est probablement quand même possible de faire mieux en les utilisant par petites touches en avant-match, par exemple, pour appuyer la description du style de jeu d’une équipe ou d’un joueur. Des analyses plus en profondeur qui sont trop peu fréquentes d’ailleurs.
Comme tous les domaines, leur popularisation passe par la manière dont elles sont abordées. Je pense qu’il faut rester le plus possible dans le concret et dans des concepts intuitifs. Pour les anglophones, cette présentation de Prozone en est un très bon exemple :
J’estime que c’est souhaitable, notamment parce que je suis persuadé que c’est une évolution logique que va prendre le football et que le public ne peut que bénéficier d’y être sensibilisé pour la suite. On en revient aussi à l’importance d’avoir des notions de l’utilisation des statistiques pour pouvoir les remettre en question, si nécessaire. Et puis, je trouve ça passionnant donc ça me semble naturel de vouloir toucher le plus de monde possible.
Très bonne idée cette série d’entretiens sur la datafoot, vivement la suite…
Cela me semble un domaine très interressant. Est ce qu’on peut se servir de la datafoot comme un moyen pour deviner les résultats des matchs à venir.. ? Ou de Deviner le nombre de buts, nombre de passes …?